Simple Beginner's AI RAG Agent with n8n
n8n is a powerful, open-source workflow automation platform that allows you to connect various apps and services without writing code. In this blog post, we’ll guide you through building a beginner's AI RAG agent using n8n, empowering you to chat with your documents and extract valuable insights. This tutorial will show you how to create a basic Retrieval-Augmented Generation (RAG) system, making it an excellent starting point for anyone looking to leverage AI in their workflows. Whether you are new to n8n or AI, this guide is for you.
Understanding RAG and Why It's Important for Your AI Agent
RAG, or Retrieval-Augmented Generation, is a technique that provides your AI agent with access to specific and current information, including data it wouldn't normally have access to. This capability allows AI agents to provide more precise, up-to-date, and contextually relevant answers. As such, RAG is quickly becoming a core component of modern AI applications, allowing them to go beyond pre-trained knowledge. This makes learning RAG skills an essential asset for anyone building AI-powered solutions. This guide will give you a solid introduction to using n8n for building a beginner’s AI RAG agent.
Setting Up Your n8n Workflow for a RAG System
Let’s dive into building your very own RAG system within n8n. We will walk you through each step, from fetching documents to integrating with vector databases. For this tutorial, we'll use Mistral for our chat model, embedding small model (due to its free API), and Pinecone for vector storage (also offering a free tier). This setup allows you to follow along without incurring costs, making it perfect for beginners.
Creating a New n8n Workflow
First, log into your n8n account and create a new workflow. If you don't have an account, you can create an account via this link and try it for free. After logging in, click ‘Create’ and select ‘Workflow’ to start. This workflow will manage the storage of your documents into the vector database.
Adding a Manual Trigger
To start our workflow, we’ll use a manual trigger. Click on the plus sign within n8n and select ‘Manual Trigger’. This allows you to manually initiate the workflow by clicking the ‘Test Workflow’ button when you are ready.

Fetching Documents From Google Drive
Next, we need to get our documents into n8n. A simple way to do this is with Google Drive. Add a ‘Google Drive’ node, selecting 'Download File' as the action. Choose to download a file ‘By URL’ from Google Drive. Copy the URL of your document and paste it into the designated field within the node. Test the step to make sure the file is being downloaded correctly and you can view it by clicking "view".

Setting Up Your Pinecone Vector Database
Now, let’s prepare our vector storage. This is where the document's content will be stored in vector format. Head over to Pinecone and either sign up for a free account or log in if you have one already. After logging in, create an index, which acts like a database. Let’s call it ‘database’.
Configuring Index Dimensions
The index requires specific dimension settings that are dependent on the embedding model. Since we're using Mistral, which isn't listed, we need to configure these manually. Click on ‘Configure Dimensions and Metric’. Set the dimensions to ‘1024’, as this is the dimension size for the Mistral embedding model we are going to be using. Keep the metric at ‘cosine’. Leave the rest of the settings as they are. Then scroll down and click on "create index".

Integrating Pinecone and Mistral with n8n
With our Pinecone index ready, let's integrate it with our n8n workflow. Add a 'Pinecone Vector Store' node to the workflow. Select 'Insert Documents' as the action. Choose the ‘database’ we just created from the list of available databases.
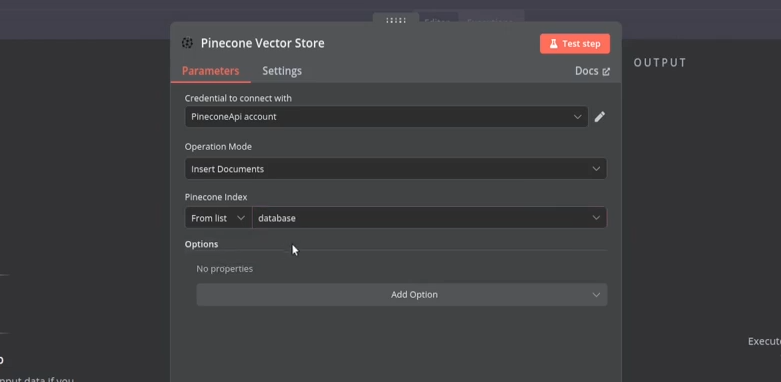
Choosing the Embedding Model
Now, we need to choose an embedding model. Click on ‘Embedding’ below the 'Pinecone Vector Store' node and select ‘Embeddings Mistral Cloud’. Pick ‘Mistral Embed’, which is the only model available at the time of writing.
Adding a Data Loader and Text Splitter
Next, click ‘Document’ below the Pinecone node and add a ‘Default Data Loader’ which is responsible for loading our document. Select ‘binary’ as the data type. This ensures the document is processed exactly as it is. Select "load all input data" as the mode. Finally, add a ‘Recursive Character Text Splitter’. This breaks down the document into manageable chunks for the embedding model. Set the chunk size to ‘1000’ and the chunk overlap to ‘150’.
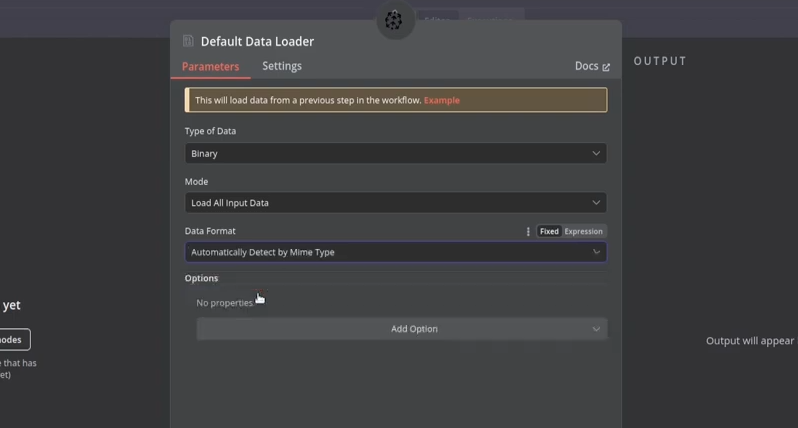
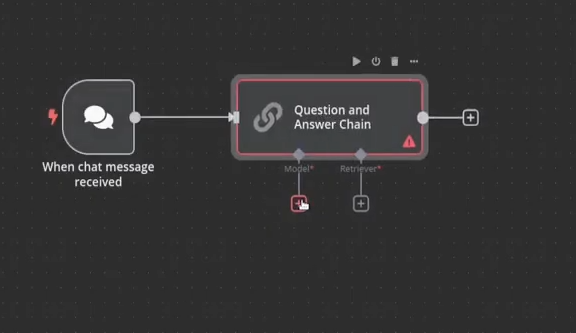
Setting up Your Question and Answer Chain
Now that we've prepped our documents, let's create the question-answering functionality. Add a ‘Chat Trigger’ node to initiate the question/answering process, then add a ‘Question and Answer Chain’ node. This is where the core logic for your AI agent lives.
Configuring the Chat Model
Configure the model by clicking the ‘Model’ section within the ‘Question and Answer Chain’ node and selecting Mistral. We are going to use Mistral small for this tutorial. Set the retriever to "vector store retriever" and the limit to 4. This limits the number of chunks retrieved for each query.
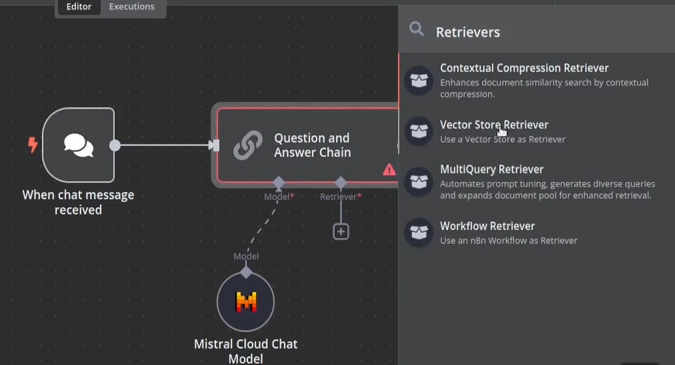
Configuring the Vector Database
Now, we need to add a vector database to use with the chat system. Add a new Pinecone node after your question and answer chain, and choose the operation mode "Retrieve Documents". Configure this node to connect to your Pinecone vector database, by using the same API key you set up in the first Pinecone node, and select the ‘database’ you created earlier. Finally set the embedding model to Mistral embed as before. Now, your chat model is set up to query your vector store using the n8n RAG integration
Testing Your Beginner's AI RAG Agent
With everything configured, let’s test our system. Click on the 'Chat Trigger' node and pose a question about your document, for example "summarize the document". You should see the system work through the steps. If successful, it will give you a summary from the information stored in the database. You can try asking more specific questions, such as “Tell me about <some concept from your document>” to test different retrieval and context capabilities of the AI agent. The response should pull information from the relevant sections of your document.
How the Process Works
First, your query is converted into a vector by the embedding model, then compared to the vectors in the vector database to retrieve similar chunks. These chunks are then used as context for the chat model which provides the final answer. This process is the basis for our n8n RAG implementation.
Conclusion
Congratulations, you’ve built a basic AI RAG agent using n8n! This tutorial demonstrates how to connect the document processing, embedding, and question/answering chains, giving your AI agent access to knowledge from your own documents. Now you can build upon this foundation for more complex and sophisticated AI workflows. Try experimenting with different documents, chat models, and other n8n functionalities to expand your knowledge. Don't forget to like the video or subscribe to the channel to stay updated on new n8n and AI content. For more information about n8n and other workflow automation tools, please visit n8n's website.